学びたいもの・作りたいものを学習グラフ図で整理してみる
Introduction
最近やっと、5週間のソフトウェア研修が終わりました!
研修中は確定定時、しかも今月は祝日・年休推奨日が重なり時間が余る余る。 緊急事態宣言中でしたし。
ということで、余った時間を勉強に使っていました。
これは余談ですが、ソフト研修の内容が本当におもしくなかった。。
これも「自分で意義ある期間にしなければ」と、勉強に対するモチベになりました笑
ただ、時間があったために色々手を広げすぎてしまった感があります。 これから確実に時間は減っていくので、うまく進められるよう、 少し整理したいなと思いました。
今回用いた方法がすごくよかったと感じるので、書いておこうと思います。
目的は、勉強しているもの、やりたいことを整理することです。 そして、勉強しているもののアウトプット先がないもの、やりたいけどインプットが足りていないものについて考えようと思います。
Learning Graph Diagram
今回は学習グラフ図をパワポで書いてみました。 まず、学習グラフ図というのは、有名・有力な人が提案した手法ではありません。 名前も勝手に自分で決めました。
こういう手法って、結局誰が提案しているかが重要なんですよね。
結局、実際の認知的な効果よりもモチベのほうが重要なので、合う合わないは個人差が大きいし。。
なので、無名無力な自分が提案してもしょうがないのですが、
「なんとなく色々勉強やってるけどあまり結果が残らないなあ」
みたいな人に使ってもらえたらと思います。
ということで早速、今回自分が書いた学習グラフ図です。

一応簡単な説明をつけておきます。
- LNPR :モデル構築からSLAM、強化学習まで、ロボティクスを理論・実装両輪で学べる書籍
- PythonRobotics :ロボティクスの様々なアルゴリズムが集められているリポジトリ
- AAAMLP :Kaggleグランドマスターによる実践的な機械学習書籍。日本語版も最近発売
- RL_sentdex :sentdexというYouTuberによる強化学習チュートリアル
- MPRG :中部大の機械学習研究室の深層学習教材リポジトリ
とにかく、ロボティクスと機械学習に興味があり、今後業務に活かしていきたいと考えています。 ただ、どちらも中途半端なので、今のうちに勉強しておこうという感じです。
食システムは業務関連かつ興味も強い分野、ドイツ語とサッカーは完全に興味です。
食システムは、ロボットキッチンやキッチンOSに今後関わりたいなと思っています。 現状の業務は主にテキスト分析ですが、、
だから自然言語処理も勉強して補強しようと思っています。
ドイツ語は音が好きだからです。
最近思うのですが、役に立たなくてもやりたいことが本当に好きなことなのでは、と。
自分はかなり実用主義なので、将来実現したいことのために空いた時間にせっせと勉強をしているわけです。
そんな中、ドイツ語は役に立ちません。たぶん多くの人にとっては英語も。 でも音がかっこいいという理由だけでモチベがわく。
こういう贅沢は大事にしないとなーと思ってたまにやっています。
けど実用主義強すぎて全然続かず、留学から帰国後4年くらい上達しないどころか退化しています。
サッカーは日本代表戦と戦術論が好きです。 RL勉強して戦術学習させてみたいな、とか。
最初は放り込んでいたものが、パスをつなぐようになり、前線からプレッシング行うようになったら面白くないですか!
問題が大きすぎるので今のPCでは無理そうですけど。
とこんな感じです。 ここまでが、今勉強していること、やりたいことでした。
Discussion
ここからは、整理した内容をもとに補強をしていきたいと思います。
ソフト研修で食システム(主にNLP)から離れすぎた感があります。 今は業務に復帰して興味が戻ってきたのですが、ここに関してもプライベートで開発をしたいなと思います。
具体的には、レシピ特徴の自動抽出です。 レシピの類似度を計算できるよう分散表現を与える方法を考えてみようかな。
これに対し、NLP関連のインプットが少ないですね。 なので、100本ノックとかやってみてもいいかも。
最近ふと、機械学習やNLPなど理論と実装の基本を押さえたうえで適切なアプローチを考えられるようになりたいな、と思いました。 勉強もがんばろう。
Kaggleは、機械学習勉強するならやるべきかなと思っていましたが、こういうコンペの問題がちょっと興味なさすぎますね。 実際の問題を解けるところが魅力かと思っていたのですが、そんな感じじゃないですね。
もう少し使えるようになってから考えようと思います。 What's cooking?よりも普通に日本語レシピの特徴抽出のほうが楽しそう。
ロボティクスは本業からまだ遠いので、やりたいことは多いけどペースは調節しないとですね。 友達と一緒に、かなり遊びに近いスタンスでやりたいと思っています。 PythonRoboticsはもう少し先になりそう。
とこんな感じで考えたことをもとに学習グラフ図を修正しました。

だいぶ食システムのやることが具体的になったし、とりあえず手をつけれなさそうなものは一旦外せたのですっきりしました。
こうやって整理すると、「やりきらないなんてよくないぞ」みたいな根拠ない罪悪感を持たずに、やるべきことを意識できてよいですね。
Conclusion
今回は、自分のインプットとアウトプットの流れを整理するために、学習グラフ図を描いてみました。
実際に、やりたいことはあるけどインプットが足りないとか、 アウトプット先をもっと具体的にしたほうがいいなとか、 色々な気づきがありました。
ROSのrqt_graphみたいに、自動的に表示してくれるものがあればいいのになあ。 いや普通にありそう。
と思って今調べたらありました。
ちょうど最近Obsidian使い始めたからラッキー!
パワポじゃなくてObsidianに移して、更新簡単にしてしまおう。 階層化とか色付けとか面倒だったら戻る。。
追記

Obsidianで作ってみましたが、あんまりきれいじゃないですね。。 それにコードもかなり長くなって管理面倒。
パワポのほうがいい気がしてくる。
大前提に、自分が見れればいい&たまに更新すればいいですからね。 パワポはサイズや位置を色々揃えようとすると面倒だけど、バランスよく並べるだけならストレス少ない気がする。
ということで、パワポでやるのがおすすめです。
Link
最後にも載せておきます
食材DB構築と代替食材提案【cooking_recipy】
Introduction
以前、レシピ生成システムを作りたい!という記事を書きました。

実はこの記事を書く前に少しだけ作っていたものがあり、それについても書こうと思っていたのですが、機械学習やロボットなど色々なものに興味がわいて書けていませんでした。
が、ToDoリストを圧迫するし、この続きも作れないのでそろそろ書きます。
今回は、食材DB構築について書いていきます。
食材DBは、食材に関する情報を持っていて、レシピと紐づけてレシピを解析したり、レシピを生成したりするために必要なデータベースです。
マクロな栄養成分、ミクロな化学成分(風味成分なども含む)、食感、切り方などの食材に関する情報を保持するものです。
前回書いた通り、FooDBなどを使えばマクロな栄養成分やミクロな化学成分のほか、多様なデータが手に入るのですが、データがでかすぎるのと、構造が複雑なのとでまだ手を付けていません。
今回は、栄養成分のみを扱うものとし、文部科学省が公開している日本食品標準成分表2020年版(八訂)を利用しようと思います。 調べていると、これを利用しているサービスや個人開発システムがかなりあるようでした。
IngredientDB
ソースコードは以下にあります。 まだPythonやGitHubに慣れておらず、使える状態にはなっていないかもです。 また、NLP・データ分析も初心者なので、テキストデータの処理も下手だと思います。
それでは、今回作ったものを説明していきます。
Data
日本食品標準成分表のホームページには、Excel形式で全食品のデータがダウンロードできます。 PythonでExcelを扱うことはできるんですが、セル結合などもあってクリーニングが面倒そうだったので、必要な部分をコピペ・CSV保存して利用します。
DB構築
まず、pandas.read_csvで読み込んだ後、クリーニングをします。
以下のコードにpandasのreplaceで邪魔だったものを一つずつ追加していきました。
df = df.replace({'Tr': '0', '-': '0', '†': '', '\(': '', '\)': '', '\*': '0'}, regex=True)
日本食品標準成分表2020年版(八訂)電子書籍によると以下のような記述があったため、0として問題ないこととします。
「-」は未測定である
「Tr(微量、トレース)」は最小記載量の1/10以上含まれているが5/10未満である
推定値として「(0)」と表示
これらの組成を諸外国の食品成分表の収載値から借用した場合や原材料配合割合(レシピ)等を基に計算した場合には、( )を付けて数値を示した
無機質、ビタミン等においては、類似食品の収載値から類推や計算により求めた成分について、( )を付けて数値を示した
次に、今回扱う栄養成分データを選びます。 全てをそのまま使うとかなり細かくなるので、一般的な栄養素を抜き出すことにしました。 ビタミンEについては、ビタミンEに属する各成分の合計で表しています。
df_main = df[
[
'l_class','WATER', 'PROT-', 'FAT-', 'CHOCDF-', 'FIB-', 'NACL_EQ',
'NA', 'K', 'CA', 'MG', 'P', 'FE', 'ZN', 'CU', 'MN',
'VITA_RAE', 'VITD', 'VITK ', 'THIA', 'RIBF', 'VITB6A', 'VITB12', 'VITC'
]
]
df_main['VITE'] = df['TOCPHA'] + df['TOCPHB'] + df['TOCPHG'] + df['TOCPHD']
ラベルと成分の対応も、日本食品標準成分表2020年版(八訂)電子書籍にあります。
- 食材分類
- 水分
- タンパク質
- 脂質
- 炭水化物
- 食物繊維
- 食塩相当量
- ナトリウム
- カリウム
- カルシウム
- マグネシウム
- リン
- 鉄
- 亜鉛
- 銅
- マンガン
- ビタミンA
- ビタミンD
- ビタミンK
- ビタミンB1
- ビタミンB2
- ビタミンB6
- ビタミンB12
- ビタミンC
- ビタミンE
代替食材提案
食材DBを読み込み、代替食材提案を行います。
まず、栄養成分の正規化と距離行列の計算を行います。 距離行列の計算には、scipy.spatialのdistance_matrixを用いています。
from scipy.spatial import distance_matrix df_normalized = (df_n - df_n.min()) / (df_n.max() - df_n.min()) self.distance_matrix = pd.DataFrame(distance_matrix(df_normalized.values, df_normalized.values), index=df_normalized.index, columns=df_normalized.index)
次に、代替食材提案を行います。
まず、入力食材との距離を、距離行列から取得してソートし、Top-10を候補とします。
[1:11]としているのは、0には、入力食材自身が入っているためです。
そして、距離の逆数を重みとします。
random.choicesを用いて、重み付きランダムで食材を1つ取り出します。
import random def get_random_substitution(self,ingredient): candidates = self.distance_matrix[ingredient].sort_values()[1:11] weights = [1/c if c != 0 else 100000 for c in candidates.to_list() ] for w,name in zip(weights,candidates.index): print(name, w) id = random.choices(candidates.index.to_list(), k=1, weights=weights)[0] return id.replace('\u3000',' '), 1/candidates[id]
代替食材提案テスト
以下のコードで、代替食材提案をテストします。 「<鳥肉類> にわとり [若どり・副品目] ささみ 生」を入力しています。
ingredientdb_file = 'ingredient.csv' ingredient = IngredientDBAccessor(ingredientdb_file) res, score = ingredient.get_random_substitution('<鳥肉類> にわとり [若どり・副品目] ささみ 生')
結果を以下に示します。 候補には、鳥肉類や脂肪の少ない魚類が並んでいます。 その中で、今回は最も栄養的に近い、「<鳥肉類> にわとり [若どり・主品目] むね 皮なし 生」が出力されました。
candidates: <鳥肉類> にわとり [若どり・主品目] むね 皮なし 生 46.46342920539068 <鳥肉類> きじ 肉 皮なし 生 38.11208426748208 <鳥肉類> しちめんちょう 肉 皮なし 生 32.15330423886038 <鳥肉類> ほろほろちょう 肉 皮なし 生 25.765611895291617 <鳥肉類> にわとり [親・副品目] ささみ 生 20.25713502192371 <鳥肉類> にわとり [若どり・主品目] むね 皮つき 生 14.822323799294368 <鳥肉類> かも あひる 肉 皮なし 生 14.702944963222343 <畜肉類> うさぎ 肉 赤肉 生 13.658679116168807 <魚類> かんぱち 背側 生 12.683994885511467 <魚類> (まぐろ類) きはだ 生 11.933984059311804 result: <鳥肉類> にわとり [若どり・主品目] むね 皮なし 生
Conclusion
今回は、日本食品標準成分表のデータをもとに、栄養成分のみの類似度による代替食材提案を行いました。
とりあえず色々初心者でも作れる代替食材提案をと考え、このようなシステムになりました。
これをレシピ生成に組み込むには、レシピ内の「鶏むね肉」と「<鳥肉類> にわとり [若どり・副品目] ささみ 生」を紐づける必要があります。
これが難しそう。編集距離だとうまくいかなかったし。
また、名前に「生」とか「ゆで」とか状態が混ざっていて同じ食材が重複して存在しています。
その辺も構造化する必要があるなあ。
結局自然言語処理になってしまいます。
今はこれを作ったころよりは少し経験値を得たので、今後改良・拡張していきたいです。
また、複数食材による代替もおもしろい・実用的そうですね。 例えば、「鶏むね肉」を「鶏もも肉」と「豆腐」で代替するみたいな。 もも肉で増える脂肪分を、豆腐で打ち消しながらたんぱく質は保つ、みたいなイメージです。
次は、レシピデータの取得について書こうと思います。
Link
GitHub - harukary/cooking_recipy: Python package for cooking recipe structuring
スプレッドシート×Google翻訳で複数言語単語帳
Introduction
今回は、スプレッドシートで複数言語の単語帳の作り方を紹介します!
スプレッドシートに日本語か英語かドイツ語を入力すると、Google翻訳を呼び出して入力された言語以外の部分を自動入力します。
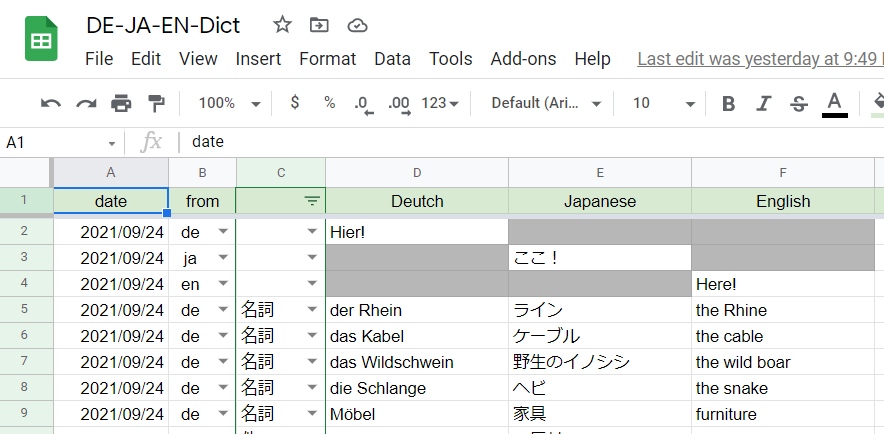
今勉強している文法書に出てきた単語を登録したので、変な単語ばっかですが、、
例えば6行目のように、「from」で「de」を選択し、「Deutsch」に「das Kabel」と入力すると、自動的に、「Japanese」に「ケーブル」、「English」に「the cable」が入力されます。
Motivation
私はドイツ語を勉強しています。
ドイツに1年留学していたこともあり、YouTubeでDW(日本のNHK的なTV局)を聞いていると、意味はあんまりわからないけど、「聞き取れ」ます。 ここでの「聞き取れる」は、音が拾えて、スペルがだいたい浮かぶくらいの意味です。
そういう意味で、ドイツ語は英語より聞き取るのは簡単な気がします。
しかし、単語の意味がわからない。 単語の意味がわかれば理解できるくらいになるんじゃないかと思い、単語を覚えようと思いました。
実際にはドイツ語は文法がめちゃめちゃ厳しい上、名詞の性もあるので、そこもしないと話すのはできないと思いますが、、
とりあえず単語。 ここで問題は3つあります。
- 単語本が売っていない
英語ならこれでもかというほど種類があるのに、ドイツ語単語は売っていないです。 ネットで検索すると少し出てきましたが、これだ!と思うものは見つかりませんでした。 検定試験を受けるなら、それに合うものはありそうですね。
- 単語本が好きじゃない
好きじゃない、、 大学受験のときも、古文単語はやらず、英単語も東進の1800とかだけで乗り切った。 TOEFL受けてた時も単語はやらなかったし。 だから単語本にピンと来なかったんですね。
たぶん、「使うかわからないものを無邪気に覚える」というのが好きじゃないんです。 だから、使うものを登録したい。
- 単語帳は登録が面倒
なんやねんて感じですけど、面倒ですよね。 単語の意味を調べ、日本語とドイツ語でキーボードを切り替えて入力していくの。 辞書に書かれた数ある意味の中で、とりあえずこれっていう意味を決めるのも地味に疲れます。
でもあれって、言語間で単語の意味の境界って違うから、とりあえずのポインタとして1つか2つ選ぶしかないと思うんですよね。 あとは、読んだり聞いたりしていくうちに、概念を修正していく。
また、ついでに英語の意味も知りたい。 そうすると、登録がさらに面倒に、、
おまけ:
また、最近データ分析も勉強しているので、こうやって集めたデータを使える形で残しておきたいということもあります。
まだ全然応用は考えていないですが、、
登録単語を自分の語彙として、例文生成とかできないかなとか。 一般的な例文より、自分が登録した単語でできた例文のほうがモチベ上がるかなとか。
だから今回の辞書の条件は以下の通りです。
- 単語登録が簡単
- 日-英-独の意味を自動入力
- テーブルデータで管理
Dictionary System
上記のようなモチベーションで「スプレッドシート 単語帳」で検索すると、Google SheetsでGoogle Translateを使えるとの情報が。
「1秒で作る!」とかブロガーって感じがしますね笑 嫌いだけど有益な情報でした。
これをもとに、単語帳システムを作っていきます。
最終的には、先ほど出した以下の画像の通りのシステムを作ります。
「from」で「ja」「en」「de」を選択
入力する箇所に「ここ!」「Here!」「Hier!」と表示
単語を入力すると、他の言語に自動的に翻訳
翻訳の順を決める
先入観として、英語をハブにしたほうがよい翻訳ができるかなと思い、以下のような翻訳順にしました。

赤い丸が、入力する言語です。 全翻訳が英語を経由するようにしました。
数式を書く
初めは、IF関数のELSE部分にIFをつなげる形で書いていましたが、ふと検索すると、SWITCH関数が見つかりました。
これを使って、各セルの数式を書いていきます。
ちなみにIF関数は、第1引数に条件、第2引数に条件がTRUEの場合の処理、第3引数に条件がFALSEの場合の処理を書きます。
IF(logical_expression, value_if_true, value_if_false)
第2,3引数にIFを書くことで、複数条件の分岐を表現できます。
そしてSWITCH関数は、第1引数に式、第2引数に式のケース、第3引数に、その場合の処理、、というように書きます。
SWITCH(expression, case1, value1, [case2_or_default, …], [value2, …])
これを使うことで今回の処理もすっきり書けました。
Detsch
2行目を使って数式を説明します。 見やすさ重視で改行・タブを追加しているので、使うときはそれらを消してください。
=SWITCH(B2,
"", "",
"de", "Hier!",
"ja", IF(E2<>"ここ!",GOOGLETRANSLATE(F2, "en", "de"),""),
"en", IF(F2<>"Here!",GOOGLETRANSLATE(F2,"en","de"), "")
)
まず、「de」が選ばれた場合、「Hier!」と表示します。
「ja」が選ばれた場合、英語から翻訳します。
ここで、条件文を
「E2<>"ここ!"」
とすることで、自動的に表示する「ここ!」を翻訳することを防いでいます。
「de」が選ばれた場合も同様に、英語から翻訳します。
Japanese
3行目を使って数式を説明します。
=SWITCH(B3,
"", "",
"ja", "ここ!",
"de", IF(D3<>"Hier!",GOOGLETRANSLATE(F3, "en", "ja"),""),
"en", IF(F3<>"Here!", GOOGLETRANSLATE(F3,"en","ja"),"")
)
まず、「ja」が選ばれた場合、「ここ!」と表示します。
残りは同様です。
Japanese
3行目を使って数式を説明します。
=SWITCH(B4,
"", "",
"en", "Here!",
"de", IF(D4<>"Hier!",GOOGLETRANSLATE(D4, "de", "en"),""),
"ja", IF(E4<>"ここ!", GOOGLETRANSLATE(E4,"ja","en"),"")
)
まず、「en」が選ばれた場合、「Here!」と表示します。
残りは同様です。
これで、「from」で選択した言語の入力欄に「Hier! / ここ! / Here!」が表示され、そこに単語を入力すると、翻訳されます。
条件付きフォーマットを適用する
見やすさと、入力すべきでないセルに入力して上記の数式を消してしまわないように、空のセルをグレーにします。
範囲を指定し、「Format」タブから「Conditional Formatting」を選択します。
条件を「Is not empty」にし、フォーマットスタイルを選びます。

プルダウンを作成する
次に、「from」をプルダウンで選択できるようにします。 以下のリンクを参考にしました。
範囲を指定し、「Data」タブの「Data validation」を選びます。
「List of items」に変更し、「ja,en,de」を直接書きます。

これで今回のシステムは一旦完成です。
Google Translate
必要に応じて、自分で調べた意味を直接書くといった使い方もできますね。
というか、Google翻訳が完璧じゃないのでそうしないといけない場面があります。
der/die/das 問題
どちらかというと、ドイツ語という言語のほうのバグのような気もしますが笑 英語に「the」をつけると「der/die/das」を入れてくれます。
ただ、日本語だとうまくいきません。 「その」をつけると、「That」として、「dieser」などがついてしまいます。
英語がハブ
ドイツ語を入力したときの日本語の翻訳が気に入らなかったので、英語を経由せずに翻訳させてみたところ、まったく同じ結果になりました。
具体的には、7行目の「Wildschwein」ですが、この意味は、「野生+豚」でイノシシです。 しかし、独→日でも独→英→日でも「野生のイノシシ」、、
どうやら英語をハブにして翻訳をしているみたいです。 独→英の翻訳がおかしいので、どうやっても日本語もおかしくなるみたいです。
なので、翻訳の順は、英語を経由せず、点線の通りでよかったことになります。

Conclusion
まとめ
今回は、スプレッドシートとGoogle翻訳を使って、登録簡単な単語帳システムを作りました。
まだまだ気に入らない点もありますが、まあまあ簡単にできたのでコスパはよかったかな。
できたものはここに置いておきます。
これはコピーなので、「単語全然増えない。使ってないやんけ!」とか思わないでください笑
今後の拡張について
品詞も使って、名詞なら英語に「the」をつけてドイツ語にする、といった拡張もできますね。
また、常に「der/die/das」が「the」に変換されるなら、名詞の場合は、独→英の結果から「the」を除くといったこともできそうです。
これ以上は、スプレッドシート数式で書くのが面倒なのでやりたくないですが、、笑
Pythonからスプレッドシートをいじる感じかな。 そしたら、Google翻訳じゃないAPI使ってもいいかもしれません。
とにかく、簡単登録単語帳ができました! また拡張したら紹介しようと思います!
Link
機械学習のメトリクス3【AAAMLP】
AAAMLP
前回に引き続き、機械学習のメトリクス、評価指標について学んだことを記録します。
AAAMLP (Approaching (Almost) Any Machine Learning Problem)という書籍で勉強した内容の整理です。
この書籍は多くの言語に翻訳されていて、2021年8月に「Kaggle Grandmasterに学ぶ 機械学習 実践アプローチ」として日本語版も発売されています。
Metrics for multi-label classification
マルチラベル問題、つまり、一つのサンプルが複数のクラスを持つ可能性のある問題に対する評価指標についてまとめます。
P@k: Precision at k
真値と予測値のそれぞれTop-kをとり、そこで重複しているクラスの割合を計算します。
def pk(y_true, y_pred, k):
if k == 0:
return 0
y_pred = y_pred[:k
pred_set = set(y_pred)
true_set = set(y_true)
common_values = pred_set.intersection(true_set)
return len(common_values) / len(y_pred[:k])
AP@k: Average Precision at k
kまでのP@kの平均を計算します。
def apk(y_true, y_pred, k):
pk_values = []
for i in range(1, k + 1):
pk_values.append(pk(y_true, y_pred, i))
if len(pk_values) == 0:
return 0
return sum(pk_values) / len(pk_values)
MAP@k: Mean Average Precision at k
各サンプルに対してAP@kを計算し、その平均を計算します。
def mapk(y_true, y_pred, k):
apk_values = []
for i in range(len(y_true)):
apk_values.append(apk(y_true[i], y_pred[i], k=k))
return sum(apk_values) / len(apk_values)
P@kやAP@kには、順序を考慮し重みづけをするものなど様々な実装があります。
Log Loss
マルチクラス問題におけるLog Lossでは、真値をバイナリフォーマットに変換し、その各列に対してLog Lossを計算します。そして、すべての列のLog Lossの平均を計算します。
Metrics for regression
回帰問題に対する評価指標についてまとめます。
Mean Absolute Error (MAE)
まず、エラーの絶対値による評価指標です。
def mean_absolute_error(y_true, y_pred):
error = 0
for yt, yp in zip(y_true, y_pred):
error += np.abs(yt - yp)
return error / len(y_true)
Mean Squared Error (MSE)
MAEに似た指標としてMSEがあります。 MSEと、MSEのルートをとったRMSEは、回帰問題において最も使われる評価指標です。
def mean_squared_error(y_true, y_pred):
error = 0
for yt, yp in zip(y_true, y_pred):
error += (yt - yp) ** 2
return error / len(y_true)
Mean Squared Log Error (MSLE)
対数を用いた評価指標もある。
これをそのまま使うのがSLE、この平均をとるのがMSLEです。
def mean_squared_error(y_true, y_pred):
error = 0
for yt, yp in zip(y_true, y_pred):
error += (yt - yp) ** 2
return error / len(y_true)
Mean Percentage Error
各サンプルのエラー率を計算し、その平均をとります。
def mean_percentage_error(y_true, y_pred):
error = 0
for yt, yp in zip(y_true, y_pred):
error += (yt - yp) / yt
return error / len(y_true)
Mean Absolute Percentage Error (MAPE)
絶対値をとるバージョンで、こちらのほうがより一般的だそうです。
def mean_abs_percentage_error(y_true, y_pred):
error = 0
for yt, yp in zip(y_true, y_pred):
error += np.abs(yt - yp) / yt
return error / len(y_true)
R-squared
R^2は、coefficient, determinationとも呼ばれます。
簡単に言うと、R^2はモデルがどれだけデータにフィットしているかを表現します。
定義をいかに示します。
[tex: R2 = 1- \frac{\sum{i=1}^N (y{t_i} - y{p_i})2}{\sum{i=1}^N (y{t_i} - y{t_{mean}})} ]
def r2(y_true, y_pred):
mean_true_value = np.mean(y_true)
numerator = 0
denominator = 0
for yt, yp in zip(y_true, y_pred)
numerator += (yt - yp) ** 2
denominator += (yt - mean_true_value) ** 2
ratio = numerator / denominator
return 1 - ratio
Matthew's Correlation Coefficient (MCC)
MCCは、-1から1の値をとります。 1は完璧な予測を表し、‐1はすべて誤る予測、0はランダムな予測を表します。
^{1/2}} ]
def mcc(y_true, y_pred):
tp = true_positive(y_true, y_pred)
tn = true_negative(y_true, y_pred)
fp = false_positive(y_true, y_pred)
fn = false_negative(y_true, y_pred)
numerator = (tp * tn) - (fp * fn)
denominator = (
(tp + fp) *
(fn + tn) *
(fp + tn) *
(tp + fn)
)
denominator = denominator ** 0.5
return numerator/denominator
Conclusion
今回は、マルチラベル問題、回帰問題に対するメトリクスについてまとめました。
この本では、評価指標の理論や性質について詳細に書いているわけではありませんでした。 自分自身、2クラス問題の指標しかよく理解していない気がします。
使っていくうちにわかるようになるのか、改めて勉強が必要になるのか。。 とりあえず評価指標がいっぱいあることを学びました。
Link
GitHub - abhishekkrthakur/approachingalmost: Approaching (Almost) Any Machine Learning Problem
機械学習のメトリクス2【AAAMLP】
AAAMLP
前回に引き続き、機械学習のメトリクス、評価指標について学んだことを記録します。
AAAMLP (Approaching (Almost) Any Machine Learning Problem)という書籍で勉強した内容の整理です。
この書籍は多くの言語に翻訳されていて、2021年8月に「Kaggle Grandmasterに学ぶ 機械学習 実践アプローチ」として日本語版も発売されています。
Metrics
今回は、マルチクラス問題に関する評価指標についてまとめます。 PrecisionとF1を書いていますが、Recall、AUC、Log Lossについても同様に計算できます。
Macro Precision
全クラスのPrecisionを計算し、その平均をとったものです。
def macro_precision(y_true, y_pred):
num_classes = len(np.unique(y_true))
precision = 0
for class_ in range(num_classes):
temp_true = [1 if p == class_ else 0 for p in y_true]
temp_pred = [1 if p == class_ else 0 for p in y_pred]
tp = true_positive(temp_true, temp_pred)
fp = false_positive(temp_true, temp_pred)
temp_precision = tp / (tp + fp)
precision += temp_precision
precision /= num_classes
return precision
Micro Precision
クラスごとのTP、FPの和を計算し、そこからPrecision を計算します。
def micro_precision(y_true, y_pred):
num_classes = len(np.unique(y_true))
tp = 0
fp = 0
for class_ in range(num_classes):
temp_true = [1 if p == class_ else 0 for p in y_true]
temp_pred = [1 if p == class_ else 0 for p in y_pred]
tp += true_positive(temp_true, temp_pred)
fp += false_positive(temp_true, temp_pred)
precision = tp / (tp + fp)
return precision
Weighted Precision
Macro Precisionと同じ計算だが、各クラスのサンプル数で重みづけをします。
from collections import Counter
def weighted_precision(y_true, y_pred):
num_classes = len(np.unique(y_true))
class_counts = Counter(y_true)
precision = 0
for class_ in range(num_classes):
temp_true = [1 if p == class_ else 0 for p in y_true]
temp_pred = [1 if p == class_ else 0 for p in y_pred]
tp = true_positive(temp_true, temp_pred)
fp = false_positive(temp_true, temp_pred)
temp_precision = tp / (tp + fp)
weighted_precision = class_counts[class_] * temp_precision
precision += weighted_precision
overall_precision = precision / len(y_true)
return overall_precision
Weighted F1
各クラスのF1の各クラスのサンプル数による重み付き平均です。
from collections import Counter
def weighted_f1(y_true, y_pred):
num_classes = len(np.unique(y_true))
class_counts = Counter(y_true)
f1 = 0
for class_ in range(num_classes):
temp_true = [1 if p == class_ else 0 for p in y_true]
temp_pred = [1 if p == class_ else 0 for p in y_pred]
p = precision(temp_true, temp_pred)
r = recall(temp_true, temp_pred)
if p + r != 0:
temp_f1 = 2 * p * r / (p + r)
else:
temp_f1 = 0
weighted_f1 = class_counts[class_] * temp_f1
f1 += weighted_f1
overall_f1 = f1 / len(y_true)
return overall_f1
Confusion Matrix
マルチクラスの場合のConfusion Matrixです。
左上から右下へのななめのラインのみ埋まるものが、完璧なConfusion Matrixです。

Conclusion
今回は、マルチクラス問題に対する評価指標をまとめました。
今回のAAAMLPを使った勉強では、マクロ・ミクロの意味や、使い道に関する違いはわかりませんでした。 これに関しては、今後どこかで補強したいと思います。
Link
GitHub - abhishekkrthakur/approachingalmost: Approaching (Almost) Any Machine Learning Problem
機械学習のメトリクス1【AAAMLP】
AAAMLP
今回は、機械学習のメトリクス、評価指標について学んだことを記録します。
AAAMLP (Approaching (Almost) Any Machine Learning Problem)という書籍で勉強した内容の整理です。
この書籍は多くの言語に翻訳されていて、2021年8月に「Kaggle Grandmasterに学ぶ 機械学習 実践アプローチ」として日本語版も発売されています。
Motivtion
私は、近い将来に海外で働いてみたいと思っています。
そのためには、グローバルに通用する資格や実績が必要です。
AWSも業務で使うため考えましたが、会社で資格を取る機会があるかなと思うのでそのときに勉強しようと思います。 あんまり自習するのはおもしろくなさそうなのもあり。
とりあえずは、Kaggleを通して機械学習を勉強しようかなと思います。
Metrics
まずは、2クラス問題に関するメトリクスを見ていきます。 書いてみたら長すぎたので、マルチクラス問題、マルチラベルのメトリクスは分けて書きます。
Confusion Matrix
まず、予測結果の分類を紹介します。
Confusion Matrixとは、予測と真値の関係を表す行列です。 2クラスの場合は2×2の行列です。 各成分をTP, TN, FP, FNと呼びます。
これ、予測と真値どっちがTrue or FalseでどっちがPositive or Negativeなのかすぐ忘れるんですよね。。

TP: True Positive
真値1に対し予測も1の場合、つまりPositiveな予測がTrueだった場合がTPです。
def true_positive(y_true, y_pred):
tp = 0
for yt, yp in zip(y_true, y_pred):
if yt == 1 and yp == 1:
tp += 1
return tp
TN: True Negative
真値0に対し予測も0の場合、つまりNegativeな予測がTrueだった場合がTNです。
def true_negative(y_true, y_pred):
tn = 0
for yt, yp in zip(y_true, y_pred):
if yt == 0 and yp == 0:
tn += 1
return tn
FP: False Positive
真値0に対し予測も1の場合、つまりPositiveな予測がFalseだった場合がFPです。
def false_positive(y_true, y_pred):
fp = 0
for yt, yp in zip(y_true, y_pred):
if yt == 0 and yp == 1:
fp += 1
return fp
FN: False Negative
真値1に対し予測も0の場合、つまりNegativeな予測がFalseだった場合がFNです。
def false_negative(y_true, y_pred):
fn = 0
for yt, yp in zip(y_true, y_pred):
if yt == 1 and yp == 0:
fn += 1
return fn
Accuracy
単純にの割合です。
Confusion matrixの成分を使って書くと、以下のように書けます。

コードは、以下の通りです。
accuracy_v2では、Confusion matrixの成分を使っています。
def accuracy(y_true, y_pred):
correct_counter = 0
for yt, yp in zip(y_true, y_pred):
if yt == yp:
correct_counter += 1
return correct_counter/len(y_true)
def accuracy_v2(y_true, y_pred):
tp = true_positive(y_true, y_pred)
fp = false_positive(y_true, y_pred)
tn = true_negative(y_true, y_pred)
fn = false_negative(y_true, y_pred)
accuracy_score = (tp + tn) / (tp + tn + fp + fn)
return accuracy_score
このAccuracyには問題があります。 それは、データセットに偏りがある場合に、モデルのよさを表現できないことです。
例えば、2クラス問題で90%の真値が1のデータがあるとします。 このとき、すべて1と予測する、つまり、何も考えていないような場合でも、Accuracyは0.9と高い値をとります。
このような場合には、Confusion Matrixの各成分を見る必要があります。
Precision
予測1の正解率を表します。

コードは、以下の通りです。
def precision(y_true, y_pred):
tp = true_positive(y_true, y_pred)
fp = false_positive(y_true, y_pred)
precision = tp / (tp + fp)
return precision
Recall
真値1の正解率を表します。

def recall(y_true, y_pred):
tp = true_positive(y_true, y_pred)
fn = false_negative(y_true, y_pred)
recall = tp / (tp + fn)
return recall
F1
PrecisionとRecallの両方が高い値をとるモデルがよいモデルといえます。
そこで、Precision とRecallを重み付き平均により合わせたメトリクスがF1です。

def f1(y_true, y_pred):
p = precision(y_true, y_pred)
r = recall(y_true, y_pred)
score = 2 * p * r / (p + r)
return score
TPR: True Positive Rate
TPRはRecallと同じ定義で、sensitivityを表します。
def tpr(y_true, y_pred):
return recall(y_true, y_pred)
FPR: False Positive Rate
1-FPRをTNR (True Negative Rate)と呼び、specificityを表します。
def fpr(y_true, y_pred):
fp = false_positive(y_true, y_pred)
tn = true_negative(y_true, y_pred)
return fp / (tn + fp)
ROC curve: Receiver Operating Characteristic curve
2クラスで閾値を変化させた場合のTPR-FPRのグラフです。

この曲線の積分値をAUC (Area Under Curve)と呼び、これも指標になる。
AUC=1は、完璧なモデルを意味する。しかし実際には、Validationでミスをしている可能性が高い。
AUC=0は、すべてを誤るモデルを意味する。反転することでAUC=1と等しくなるため、AUC=1と同じくValidationでミスをしている可能性が高い。
AUC=0.5は、完全にランダムなモデルを意味する。まったくあてにならないモデルであるといえる。
具体的に、PositiveサンプルとNegativeサンプルをそれぞれランダムに取り出したとき、PositiveサンプルがNegativeサンプルより高い予測がされる(つまり正しい予測)確率をAUCは表します。
問題によって、結果として確率が欲しい場合と、クラス(0 or 1)が欲しい場合があります。 もしクラスが欲しい場合は、適切な閾値を選ぶ必要があります。
この閾値の選択に、ROCカーブは有用です。 TPRが高くFPRが小さい、具体的には、グラフの左上の角の閾値がベストです。
Log Loss
2クラスの場合の定義を下に示します。
ここで、はそれぞれ、真値、予測値を表しています。
Log Lossは、誤った予測や大きく異なる予測値に対し、大きなペナルティを課します。 たとえ正解しても、信頼度が低ければ値が小さくなります。
例えば、精度100%の予測をした場合でも、予測値が閾値付近で信頼度が高くない場合、Log Lossは大きくなります。
def log_loss(y_true, y_proba):
epsilon = 1e-15
loss = []
for yt, yp in zip(y_true, y_proba)
yp = np.clip(yp, epsilon, 1 - epsilon)
temp_loss = - 1.0 * (yt * np.log(yp) + (1 - yt) * np.log(1 - yp))
loss.append(temp_loss)
return np.mean(loss)
Conclusion
一応勉強したことを記録しようとしたら、長すぎて3つに分けました。 それでもかなり長い。
技術ブログをやっている方々はどんなパイプラインでやっているのかすごく気になりますね。 一つ書くだけで心折れそうになる。
とりあえず2クラス問題を前提に、機械学習のメトリクスを整理できました。 次の多クラス問題と、マルチラベルのメトリクスは、今回出てきたメトリクスをもとにしてできているので、少しは楽になるかな。
Link
GitHub - abhishekkrthakur/approachingalmost: Approaching (Almost) Any Machine Learning Problem
レシピ生成アプリの紹介【Plant Jammer】
はじめに
「レシピカスタマイズしたり生成したりするサービスないかな」
ふと調べたときに出てきたPlant Jammerというアプリを紹介します。
まさに自分の理想に近いサービスでした。
料理フレームワークに冷蔵庫にある食材を入力すれば、おいしい料理にするために必要な要素、食材候補を提示してくれます。
そこに、機械学習により抽出した、風味や食感に基づくフードペアリングを使っているとのことです。 すごくおもしろそう。
Plant Jammerとは
「Plant Jammer(プラント・ジャマー)」は、AI(人工知能)を活用し、 家庭にある食材や調味料を入力するだけで、 ヘルシーで美味しい料理のレシピを自動生成するスマホアプリ [1]

酸味、塩味、苦味、うまみ、辛み、油分、歯ごたえ、柔らかさ、新鮮さ、香りという、 美味しさの中心的要素を整理したうえで、 独自のニューラルネットワークに300万件のレシピデータを与え、 美味しさを形成する"フード・ペアリング"のパターンを学習させることに成功した。 [1]
です。 また、生成したレシピからショッピングリストも作れます。
アプリ説明から見たポイントは以下の通りです。
- ベジタリアンレシピ限定
- ターゲットは「料理を学びたい初心者」から「新しい風味の料理を発見したい経験者」まで
- プロ料理人とデータサイエンティストの協働により開発
まず、ベジタリアンレシピ限定。
ここは自分が使うという面では惜しいですね。 肉も魚も食べたい。
ただ、ベジタリアン料理を作ろうとすると、旨味・コクにおいて物足りなくなってしまうことが多いですよね。 なので、AIによっておいしいレシピを作るための支援が受けられるのは魅力的です。
そういう面で、ベジタリアンを始めるきっかけになるかもしれないですね。
次にターゲット。
まさに素人からプロ(経験者)まで使えるアプリ。
私には、こういうターゲット設定の製品・サービスがとても魅力的に感じます。
例えば、スマホカメラは、世界から写真を増やしたと思います。 それまでのデジカメやガラケーのカメラは、正直印象的な写真は撮れなかったはずです。 それがスマホが高性能のカメラを備えるようになり、写真をメインにしたプラットフォームが増えました。 これにより、世界から写真、美しい写真を増やしています。
同様に、世界から料理を増やすような、そんな製品・サービスを作れれば楽しいだろうと思います。 Plant Jammerのアプローチは、自分にとっては好きなものです。
最後に、プロ料理人とデータサイエンティストの協働により開発されている点。
これは技術系としては最も気になる部分です。 冒頭に、NNにより300万件のレシピを学習し、フードペアリングのパターンを抽出したとありました。
ここでレシピ構造化をどのように行ったのかすごく気になります。
FooDBのようなデータベースをもとに食材特徴ベクトルを付与したのだろうと思います。 そうすれば、類似度や加算などの計算が簡単にできますからね。 でも、(公開されているデータでは少なくとも)足りないデータがあると思います。 それをどう調達したのか、気になる。。
使い方

簡単に使い方を紹介します。
無料版でも少しの基本レシピを使うことができます。 有料版で何ができるのかはよくわかりません。
まず、基本のレシピを選びます。 今回はStew(煮込み)を選択しました。
材料には玉ねぎ、アスパラガス、マッシュルーム、風味には、パプリカパウダー、サワークリームを選択してみます。
すると、おいしい料理にするために、不足している要素とその食材候補を提示してくれます。今回は、Oil(油脂)とCrunch(カリッと食感)が不足しているそうです。
そこで、バターを選ぶと、おいしさスコアが86%→93%に上昇しました。
Crunch項目は選択せずにレシピを生成します。 ここでCrunch項目も埋めると、おいしさスコアは100%になります。
生成結果には、材料の分量や調理手順が含まれます。
分量や手順の生成方法も気になります。
最後に
まさにやりたいことに近いアプリを見つけてしまいました。 2018年にすでにやられています。 なので研究などもっと調べれば、個人でもいいとこまでいけそうな気がします。 それが知れたことは少し嬉しいです。
そして使ってみると、UIがかわいいんです。 料理を一つ抽象的なレベルに飛ばしていて、リアルには何が出来上がるのかわくわく感があります。
料理の科学に興味がある人とかが好きなUIだと思うので試してほしいです。
Link
[1] 食材の相性をAIで解析、最適なレシピを自動作成する「Plant Jammer」
[2] Plant Jammer | AI, recipes and sustainability
[3] Create Recipes and Shopping Lists - Plant Jammer - Apps on Google Play